






Written by Hung Minh Nguyen, AI-Data Engineer
Model Serving problem
AI/Deep Learning models have been taking over many services that previously required human intervention. However, to bring AI services online, engineers may encounter a number of issues. Model maintainability, efficiency, security, and reusability are some of the common problems in production deployment. Firstly, researchers tend to use different frameworks (Pytorch, Tensorflow, MXNet) and various SOTA networks (Resnet, Transformer, RNN...) to achieve the highest level of accuracy possible. This may cause maintainability issues for engineers in model integration. Secondly, in most cases, an end-to-end AI service is a combination of several models. When services need to be deployed multiple times due to service requirements (such as QPS and latency), GPU usage efficiency and model reusability issues are likely to arise. In this blog, we will discuss how to solve these problems by using TensorRT and Triton Inference Server (Triton), and how we serve our AI/Deep Learning models in production.
TensorRT
TensorRT is NVIDIA's parallel programming language built on CUDA. It optimises inference time and GPU usage for AI/Deep Learning models trained by other frameworks (Pytorch, TensorFlow, MXNet). TensorRT also supports different precision inference INT8 and FP16 that can reduce the latency.
_01.jpg?width=600&name=TensorRT-and-Pytorch-benchmark-(batch-size-32)_01.jpg)
TensorRT and Pytorch benchmark (batch size 32)
Here, we compared the inference time and GPU memory usage between Pytorch and TensorRT. TensorRT outperformed Pytorch in terms of the inference time and GPU memory usage of the model inference where smaller means better. We used the DGX V100 server to run this benchmark.
Triton Inference Server
There are a couple of available model-serving solutions including TFServing and TorchServe (currently still under experimentation). Each of them, however, only focuses on Tensorflow or Pytorch model deployment, respectively. We have chosen Triton, developed by NVIDIA, as our model serving due to the following characteristics:
-
Triton supports hosting/deploying models from different frameworks (TensorRT, ONNX, Pytorch, TensorFlow) and provides a standard model inference API which makes maintainability easier for engineers.
-
Dynamic batching inference
-
Model inference in parallel (concurrency): different deployed model instances can run in parallel. *Model reusability and microservice mean different clients/services can share a single model.
-
Model repository: model files can be stored on the cloud (AWS s3, Google Cloud Storage) or local file system. Even if a model is running on Triton, Triton can still load the new model or new configuration updated from the model repository. This also provides better model security and a better model upgrade mechanism.
-
Model versioning
-
Server monitoring: statistic data of GPU and requests are provided in Prometheus data format.
Efficiency aspect
Two main features that significantly optimise GPU usage are batching inference and concurrency.
- Batching inference
With Triton, individual requests are batched and executed together, which improves throughput remarkably but does not yield much latency. As we can see below, when we compare batch 8 to batch 1, the QPS improves four times while adding a little extra latency (from less than 1 ms to less than 2 ms). Another point of interest is that the QPS will not improve after the batch size reaches a threshold. However, the latency will increase instead. From our example, even if we increase the batch size to more than 16, the QPS is still at about 14,000 while the latency increases along with batch size.
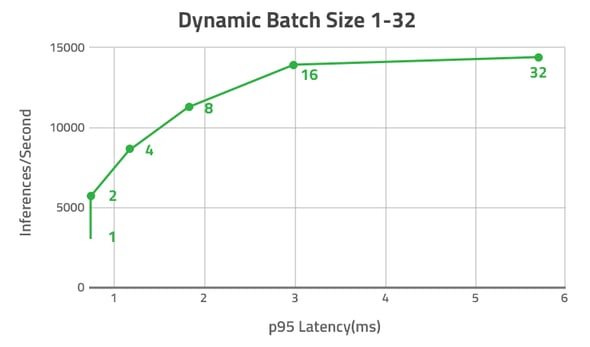
Model inference example using batching on Triton, source NVIDIA GTC 2020
Triton allows us to configure the trade-off between QPS and latency through model configuration.
dynamic_batching {
preferred_batch_size: [ 4, 8 ]
max_queue_delay_microseconds: 100
}
preferred_batch_size: indicates which batch size the inference server should attempt to create before fetching data to the model to run.
max_queue_delay_microseconds: changes the behaviour of inference based on the frequency of incoming requests. If new requests come in and the inference server can form a preferred batch size, the data will be immediately sent to the model to execute. If no preferred batch size can be created within `max_queue_delay_microseconds`, the server will only execute even though the data is not a preferred batch size.
- Concurrency
For end-to-end services, concurrency model inference means that different requests can be processed in parallel because one request does not wait for another request to first complete the entire pipeline. This feature allows us to maximise the usage of GPU on production servers.
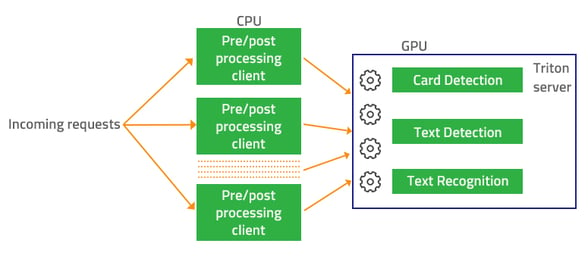 Concurrency in OCR service
Concurrency in OCR serviceAs shown in the figure above, different incoming requests can be processed at the same time in the OCR pipeline, which contains three models (Card Detection --> Text Detection --> Text Recognition). Some will be at the card detection model, and some will be already at the text detection or text recognition model. All three models are able to run simultaneously on GPU. Therefore, the GPU can be utilised very well when hosting multiple models on Triton.
How much TensorRT and Triton accelerate our AI services
To demonstrate the efficiency of services using Triton as model serving over services without model serving, we have done several service benchmarks to compare the QPS and GPU usage as shown below:
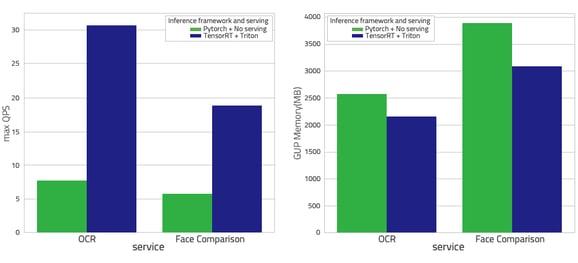
End-to-end services benchmark on server T4
By using TensorRT and Triton, we have improved QPS by almost four times for all of the services. OCR QPS improved from 7 to almost 31 and Face Comparison QPS increased from 6 to 19 while using a similar or smaller amount of GPU memory.
For latency, the overall latency of services served by TensorRT and Triton has been improved by about 20%, according to our cloud services as monitored.
Conclusion
We mainly cover the efficiency aspect of using TensorRT and Triton as model-serving for our services in this blog. There are still a number of aspects we have not discussed, such as comparing Tensorflow performance with TensorRT (we believe Tensorflow performance should not be much different from Pytorch), CPU and RAM utilisation when using Triton, or how to convert the trained models to TensorRT, and maintaining, reusing, and securing those models using Triton in production. As we are also building internal tools to achieve these goals, we hope we will write more blogs about these tools in the future.



