






Written by Jiangbo Yu, AI R&D Lead
Data Factory
As Google made AI history by beating the world's "Go" champion in 2015, the industry began to usher in a wave of deep-learning. Industry and academia entered a highly integrated period, in which many academic leaders have entered the industry ready to show their skills. After several years of rapid innovation and development, deep-learning models are becoming increasingly mature in certain applicable areas. Simultaneously, artificial intelligence (AI) computing power is growing at a rate of ten times per year, providing a solid technical foundation for the widespread use of AI.
ADVANCE.AI has been experimenting in the direction of deep-learning applications for three years. As the business expands and the demand continues to grow, the main challenge for deep-learning has gradually evolved from the model to the data itself. For example, in the ID OCR application area, the model has gradually converged, and how to efficiently obtain data has become the biggest bottleneck of the product.
The pain points in terms of data are mainly from:
-
A portion of the data being highly sensitive, such as personal identity information or medical data. The lack of valid data significantly affects the development of services.
-
The high volume of data annotation or the high cost of annotation leading to increased research and development costs.
AI needs to solve the most practical problem of the cost before it can be widely used. How can we reduce the cost of data? First, we start by drawing a core distinction between approaches of deep-learning models for labelled training data and weak supervision at a high-level. Weak supervision is about leveraging higher-level and/or noisier input from subject matter experts (SMEs).1
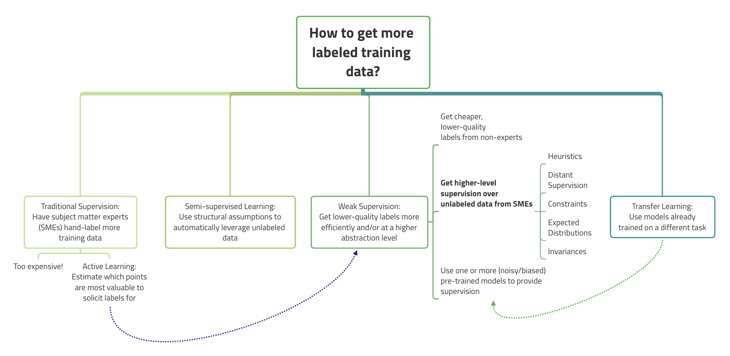
Figure 1 the core distinction between approaches of deep learning models for labelled training data and weak supervision2
The following are ADVANCE.AI's exclusive insights summarised from the continuing experiments:
-
Semi-automated annotation:
Using existing models to assist in an annotation can effectively reduce its cost, and manual adjustment of the automatic annotation results can improve the accuracy of annotation.
-
Using some generative models, such as simple rules or generative models, can be used to generate model training data.
-
Using Hard Example Mining:
Another effective way to reduce the cost of annotation is to narrow the scope of labelling, which requires applying Hard Example Mining to filter some data (such as false positives) to avoid invalid labelling, and these samples can help improve the accuracy of the model.
-
Adopting semi-supervised learning can help us improve data representation by leveraging a huge amount of unlabeled data available online.
-
Creating a standard data platform system can provide efficient, standard data annotation and learning feedback mechanisms. The system needs to provide channels for a large number of nonprofessionals to input their own data tags so that the system can learn accordingly and continuously evolve its decision-making capabilities.
Based on the above and the anticipation of Software 2.0, the importance of data processing in the AI industry is self-evident.
We believe that many industry professionals also have a corresponding understanding of quickly and efficiently performing data processing operations through tools and platforms to realise standardised processes, get easier access to mass production of efficient models, and improve data annotation worker efficiency. Finally, It will benefit the application of AI technology into various industries and significantly reduce AI application costs.
ADVANCE.AI's product you need to know
TDD (Training, Development and Data) is a machine-learning system independently developed by ADVANCE.AI, specialising in providing standardised model development and data processing functions. The system currently supports the rapid iterative development of all standard AI products and will support self-service user side AI functions in the future.
1. Sourced from http://ai.stanford.edu/blog/weak-supervision/
2. ditto.



