






Written by Lilong Qian, AI-Research Scientist
The history of OCR
Figure 1: OCR service that allows to convert scanned images to text
The Optical Character Recognition (OCR) indicates how to extract the textual and semantic data in the image files. In 1929, Tausheck first proposed the conception of OCR – utilising the machine to read characters and numerals. However, it was still just a dream until the arrival of the computer age.
Some researchers started researching character recognition (basically on text recognition, specifically recognising numerals) early in the 1960s. During that period, OCR technology had been used in mail-sorting by the postal service to recognise zip codes in the U.S.
However, early-phased OCR technology had its limitations---it was only capable of recognising high-quality text. Thus, the text used for OCR needed to be perfectly straight, clear, and printed in the single font that OCR devices were programmed to recognise.
Early-phase OCR technology's recognition process was needed to compare the shape between the given character and the one previously stored in the database, then to find the best match for recognising.
As computer processing developed in the 1960s and 1970s, the Omni-font[1] OCR reader became available. Although font has various design styles, this kind of scanner was able to recognise the general form and shape, instead of looking for an exact match.
The OCR devices we have today were launched by Kurzweil Computer Products, Inc., which was founded in 1974. However, it wasn’t until the 21st century that OCR came into its own. A wide range of OCR applications become a reality with the combination of internet technology. Additionally, with the innovation of recognition algorithms, optical scanners enabled the handling of output in higher resolutions. This innovation of OCR brought about some new and exciting applications including vehicle license plate recognition, identification card recognition, receipt recognition and other customised OCR services. OCR has revolutionised the way we do business and our daily lives. It has been widely used all over the world.
Creativity comparison: machine-learning-based OCR vs traditional OCR
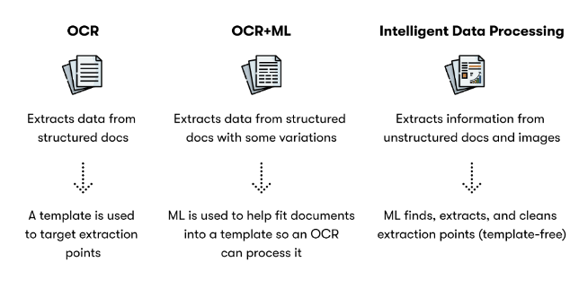 Figure 2: Traditional OCR vs machine-learning-based OCR
Figure 2: Traditional OCR vs machine-learning-based OCR
Traditional OCR techniques achieved great success in the last 20 years, specifically in scanning documents. The whole procedure of the traditional OCR method follows three main steps:
-
Image pre-processing
-
Text line extraction
-
Text line recognition
The image pre-processing step simplifies the complexity of OCR processing and contains the function of geometric rectification, blur correction, and illumination rectification.
With image pre-processing, the text line is extracted before the text recognition via image binarisation, page layout, and line segmentation. In the final step, character segmentation and character recognition are used to convert the image into text.
The traditional OCR can only handle relatively straightforward cases, for example:
-
Simple page layout
-
Strongly separable for foreground and background information
-
Easy segmentation for each text character
%20vs%20scanned%20document(right).png?width=549&name=photo%20taken%20by%20the%20camera%20(left)%20vs%20scanned%20document(right).png)
Figure 3: photo taken by the camera (left) vs scanned document(right)
However, the demands for text recognition in natural scenes has arisen. The natural scene circumstances are more complicated than the traditional scenes in illumination, page layout, and contain more noise.
With deep learning development, we can solve the traditional OCR limitation with the new algorithm technology. A complete machine-learning-based OCR process can be simplified into two steps now: text detection and text recognition. Unlike traditional OCR, the network of machine-learning-based OCR can automatically learn a useful feature for the detection and recognition model with a large amount of data, freeing the engineer from the manual feature engineering process. It can also produce more generalisable results than traditional OCR for complicated circumstances such as fonts in different shapes, colours, and sizes, and images with various qualities, backgrounds, illumination changes, and geometric distortion. This is because the network of machine-learning-based OCR enables the extraction of an invariant feature regardless of changes. Also, its processing speed is much faster than the traditional OCR due to the help of large-scale GPU parallel computing.
Machine-learning-based OCR has more benefits than the traditional way because of data availability and network design, which lower the difficulty of feature engineering processing.
Difficulties in machine-learning based OCR
It is widely believed that machine-learning-based OCR outperforms the traditional way. However, deploying a complete pipeline for the OCR system is still not an easy task. The difficulties mainly lie with:
-
Availability for a large amount of data
-
Efficient network design for high accuracy
-
Low computation cost
Developing a traditional OCR model may only need tens of hundreds of samples. However, training a network to perform the machine-learning-based OCR, which satisfies the requirement accurately, usually requires a lot of time and resources to obtain the basic dataset. Also, another pain point of machine-learning-based OCR is the annotation precision of data collection. If a certain pattern mistake happens too frequently, the model will learn the pattern through training. For example, if an annotator labels all lower-case letters with upper-case letters, the model will also predict upper-case letters with high probability. In other words, noised data always affects the accuracy of the model, which is unavoidable when people are doing annotation tasks.
Designing efficient networks is also full of challenges. A network with good structure achieves better performance, as it reduces training difficulty. However, variance between networks is as countless as the stars in the sky. If we want to find the best OCR model for training the accuracy, the only way is to utilise the common conclusions and experimental results because we cannot try them individually. In practice, the network requires an additional design to make it "small" and "fast" because an extensive network that obtains high accuracy sometimes may process slowly and have a huge file size. Also, it needs to be able to run in parallel mode, which utilises GPU's capability. Otherwise, it may be too slow for real-time applications.
In sum, it is necessary to make consistent efforts to keep the system extensible and user-friendly since adopting research technology into real use scenarios is essential.
Creativity in ADVANCE OCR implementation

Figure 4: OCR implementation
In the development of ADVANCE.AI's OCR technology, we also faced some difficulties. Fortunately, we reduced the obstacles with the following ideas:
-
Automatic data cleaning
-
Efficient network designing
-
Pipeline integration and maintaining
As mentioned above, the most common limitation of machine-learning-based OCR is the annotation precision of data collection, on which a high-accuracy model is based. We use deep learning algorithm technology to improve the quality of data annotation at ADVANCE.AI through the following steps:
First, we trained baseline models and estimated the confidence score that the annotation is correct. Second, we selected the data set that needs to be annotated several times repeatedly instead of annotating the data independently to guarantee the data quality. Another method to improve data annotation productivity is using the model to find hard examples for training, instead of adding data by random choice.
We also made many efforts to improve the ADVANCE OCR network. First, we kept track of the latest research in the related fields and considered which can be learned to improve results. For example, we learned that we could eliminate the LSTM module in text recognition by replacing it with one module in the NLP field, which is much faster while obtaining better performance. Second, we adjusted the network to fit the productions. For example, we selected and compressed the appropriate network to satisfy the accuracy and speed requirements, while also reducing the cost.
A healthy and extendable OCR system is the key point for providing good service for clients. With a reliable system, we can do testing, debugging, and technological evolution as quickly as possible and save human resources departments from repetitive tasks.
Figure 5: OCR implementation
Future directions in OCR applications
It has been quite the journey for OCR from the musical book-reading device in 1914 to today's myriad applications. We have made great progress in developing ADVANCE OCR, and we continually strive to improve the quality and the functionality of our services.
-
Data collection
Data is precious for A.I. related business. Undeniably, improving the effectiveness and efficiency of data collection is essential. For efficient data collection, we can keep moving by researching at least two methods —"synthetic data" and "auto-annotation."
Unlike the traditional synthetic way, GAN (generative adversarial network) is a good choice for generating close enough data to real data, eliminating numerous manual annotations tasks. Auto-annotation is a method that combines model training and data annotation.
However, there is a problem in current model development that data annotation is separated from the training, resulting in several obstacles. For example, we cannot control if the data annotated is what the model needs, and we also do not know the exact amount of data needed. Currently, it is all based on the engineers' experience, which is, of course, not always as accurate as expected.
-
Model research
Besides the data, the model is critical, and model research is prevalent as well. In the model research field, the following directions that we are worthy of keeping track in the future: "AutoML" and "Model Compression".
AutoML enables automatic identification of a better network structure and speeds up the progress of research and product iterations. Model Compression helps find more light-way models that can save resources and develop more mobile-device services.
There are too many aspects that need to be improved. Although there might be some goals we cannot achieve, we still hope to develop more ideas to improve our products. In the future, we will work with new partners to increase productivity from our ADVANCE OCR system, contribute more to society's research, speed up technical evolution, and strive for a world of dignity, sustainability, and prosperity.
[1] Omni-font: any font that maintains fairly standard character shapes



