






Comparison Between Using Deep Learning and Conventional Machine Learning Techniques for Extracting Features of Event Tracking Data
Deep learning has brought about great breakthroughs and innovations to the application of artificial intelligence (AI) technology, such as computer vision (CV) and natural language processing (NLP). It also significantly improves the prediction accuracy of related models, promoting the essential changes of technical applications. That is why deep learning has attracted much attention from the industry in the past five years.
Compared with conventional machine learning approaches, deep learning does not require much feature engineering and is not affected by the sample quality of data and features. It is less dependent on expert knowledge and provides more possibilities for model training.
Deep learning combines and generates features based on neural networks. It has strong model learning capabilities and can automatically complete feature engineering tasks for conventional machine learning. It also extracts more comprehensive data. Therefore, deep learning has an advantage over conventional machine learning approaches in training models on data sets with millions of rows. It is also more efficient in training models on samples of image or language data that cannot be processed through feature engineering.
In regard to risk control of the Internet finance industry, machine learning models are widely used because most data in this industry is behavioral series data closely related to time. AdvanceAI wants to apply deep learning theories in feature engineering of these machine learning models. This approach is expected to use neural networks to extract more efficient time-series features to improve the performance of related models.
This article reveals the benefits and drawbacks of using the conventional feature engineering technique and the LSTM-based RNN in extracting features of event tracking data during data mining. The conventional feature extraction technique is widely used in machine learning. The long short-term memory-based recurrent neural network (LSTM-based RNN) is a typical model used in deep learning, a subset of machine learning. This article explores the mechanism of combining deep learning and conventional machine learning models for improving the efficiency and quality of data mining and model training during Internet-finance risk control.
Introduction
1. Extract event tracking data
The event tracking data is collected through tracking the operations of users. When an operation of a user meets a preset condition, such as clicking a specified button or entering a specified page, event tracking is automatically triggered to collect and store the related data. The event tracking data has extensive commercial value after going through big data processing. In Internet finance and credit service scenarios, the related event tracking data can be used for user profiling and user behavior analysis. You can also use such data to drive operational and marketing decision-making, product recommendation, and risk identification. As a type of important characterization data for analyzing user credit and fraud risks, the event tracking data is completely heterogeneous with the data types provided by third-party databases for related requirements. However, the collection of the event tracking data is usually unstable and the data volume is usually large. It is difficult to use such data in feature engineering.
In the comparison experiment described in this article, AdvanceAI uses the event tracking data collected for users within 30 days before they receive a loan or a credit line from a bank. This data covers different service scenarios before and during the grant of the loan or credit.
After preliminary data cleansing, data samples used in the modeling of this comparison experiment include an average of 288 event tracking data points for each user. In the sorted data, 669 data points are distributed at the 95th percentile and 1,074 data points at the 99th percentile. In the final dataset, 1,000 data points (at the 98.7th percentile) are extracted from each sample. Rows after the 1,000th row are truncated.
The following table (Table 1) lists the four original fields used in event tracking data collection for this experiment.
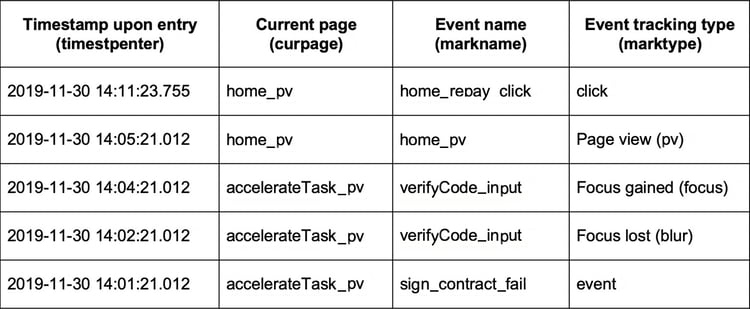
△ Table 1: Original fields of event tracking data
2.Extract PV features through feature engineering
(1).Feature collection
Aggregate the PVs of users for periods of 1 day, 7 days, and 30 days. Then, calculate the total number of times the same user views the same page (cnt), maximum duration (max), minimum duration (min), average duration (avg), and total duration (sum) of each PV of the user.
(2).Feature building
Number of derived feature variables = PVs × 5 × 3
(3).Feature filtering
Filter PVs based on feature importance, business requirements 1, and stability. Select the top n PVs with the highest stability and the lowest Psi values. Extract 15 dimensions of features for each PV. The total number of feature dimensions is n × 15. n is the number of PV types. If n is less than 20, the total number of feature dimensions is less than 300.
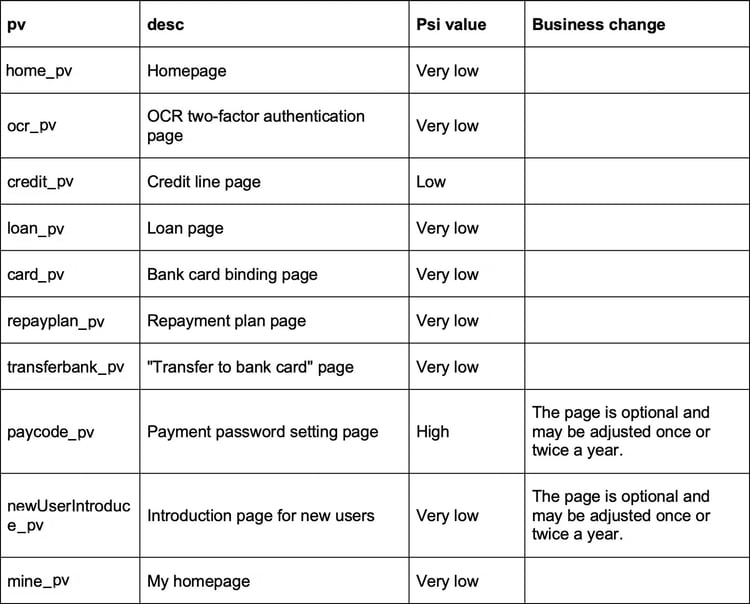 △ Table 2: PV feature collection table
△ Table 2: PV feature collection table
3. Generate PV features using deep learning
Event tracking data on web pages includes data of multiple types, such as pv, blur, focus, event, and click. AdvanceAI intends to use the LSTM-based RNN to build end-to-end models and combine user clicks with the loan repayment acts of users to extract valid time-series features.
(1).Data preprocessing
The raw event tracking data is collected using fields listed in Table 1. The following table lists the sequence pattern of the pre-processed data.
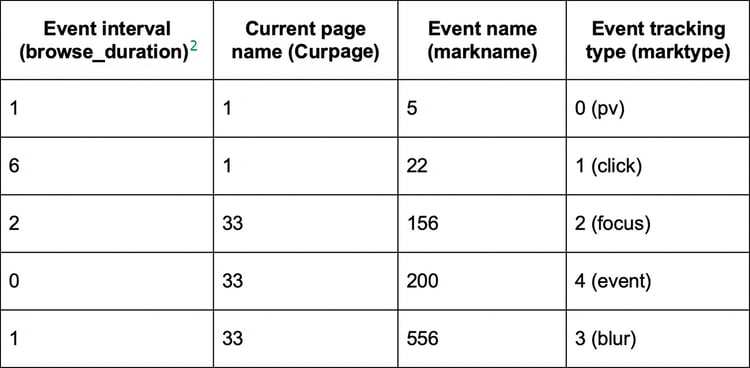
△ Table 3: Sequence pattern of deep learning data after preprocessing
(2).Input data format
Each user behavior is represented using 1,000 four-dimensional time-series data points to generate a matrix where input_shape=[n, 1000, 4]. If the number of data points is less than 1,000, use 0 to fill in the missing values.
(3).Output data format
Predict whether the repayment of a loan is overdue: output_shape=[n, 1].
(4).Algorithm execution
The integration of the two-layer LSTM-based RNN and the layer normalization technique accelerates the convergence process. The use of focal loss increases the learning capability of the model on samples where the characterization data is insufficient.
Experiment result
AdvanceAI uses an LSTM-based RNN to extract the time-series features. Compared with statistical time-series features extracted through time-window slicing using the conventional feature engineering approach, the deep learning approach provides higher prediction accuracy. The area under the curve (AUC) is increased by 0.02, from 0.63 to 0.65. Based on the result of this experiment, deep learning approaches such as an LSTM-based RNN can more efficiently extract time-series features. Deep learning approaches provide better performance in data mining of time series data in the Internet finance industry. They are an effective complement to conventional feature engineering techniques.
[1]Note: You can filter features by business requirements because the page features vary with the channels and stages. Before you filter features by business requirements, consult the related product owner in advance. Select pages that are currently in use and have remained stable for a long time. Non-PV feature data involves too many events and you can only design features such as clicks and time intervals based on your business experience.
[2]The values in the browse_duration column of Table 3 are generated based on the timestpenter column. Each value in the browse_duration column indicates an interval between the current event and the last event. The values in the curpage, markname, and marktype columns are directly mapped into numbers using LabelEncoder.



