
中

作者:曾洪勇 职位:高级数据科学家
模型开发注意事项
有调查表明,80%左右的信贷风险来自于贷前审批环节,由此可见贷前风控在信贷领域的重要性。申请评分卡模型开发有其特殊性,本篇文章将按模型开发步骤枚举信用卡业务申请评分卡模型开发中的典型场景及注意事项,以供探讨:
1、样本抽取
申请评分卡模型典型抽样方法如下:首先抽取全部“坏样本”;然后随机抽取“好样本”,如果“好样本”数量低于“坏样本数”的10倍,则抽取全部“好样本”,否则,“好样本”的抽取数量定为“坏样本”的10倍;如果需要把“灰度样本”和“拒绝样本”放入建模样本,也可以使用类似的方法进行抽样。最后,一般将随机抽取抽样后总样本的70%为开发样本,30%为验证集。
2、特征工程
开发申请评分卡时可用数据一般包括申请信息、人口信息、征信信息、多头借贷和运营商信息等多个维度,在模型构建时,除了使用原始的这些变量信息,特征衍生也很有必要。
常见的特征衍生方法有时间滑窗统计、FRM分析、不同维度交叉分析等。
3、模型选择
目前,在信用风险模型开发中可供选择的算法很多,主流的模型包括逻辑回归、基于决策树的集成模型(XGBOOST、LIGHTGBM、CATBOOST)等,此外深度学习在金融风控场景的应用实践也越来越多。具体模型方法的选择必须根据实际业务需求和系统上线实施的便利程度等来确定。
4、模型表现评估
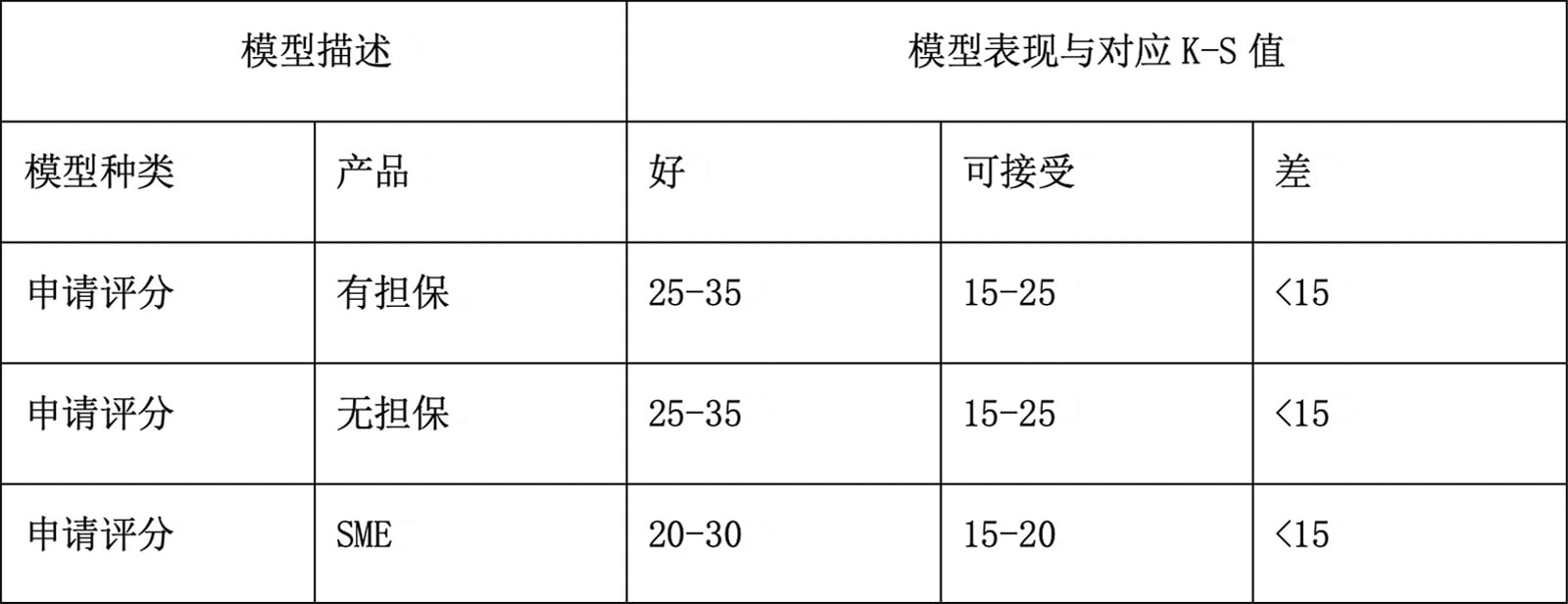
区分度是衡量申请评分模型区分目标变量、识别好坏样本能力的常用指标,通常使用K-S和AUC(GINI)系数来衡量,以此评估模型区分好坏样本的能力。此外,常用的PSI指数可以对样本群体的(时间)稳定性进行衡量。下表是申请评分卡模型表现评估K-S值表现度的一些实践总结,可供参考:
5、拒绝推断
申请评分卡有一个特别需要注意的问题,那就是建模样本的偏差性和拒绝样本的表现推测。在进行贷款审批时,通常一定要根据既定的拒绝条件进行考量,比如“评分分值是否符合要求”“收入水平是否符合要求”“历史是否逾期”等,因此,通过审批的样本并不是申请样本的无偏代表。如果申请评分卡只是基于通过的样本建模,可能会对预测结果造成一定程度的偏差。
拒绝推断的步骤如下:
1)构建已有样本模型(Know Good Bad Model),已有样本模型是进行推断的基础。
2)进行好坏样本分配。使用已有样本模型为拒绝样本打分(KN_SCORE),并按照已有客户模型计算出的分数与好坏比率的关系,为拒绝样本分配好坏比例。
3)基于已有客户和表现推断后的拒绝客户的总样本,建立新的评估分数,并分别基于已有客户群体和拒绝群体,建立新旧评分的关系。
4)判断好坏分配过程的离散度值是否达到了预期目标,标准如下: “离散度下限” 小于 “选取分位点在已有客群和拒绝样本上的好坏比例差异(DELTA)”小于“离散度上限”
在实际开发中,离散度上限和下限可分别选取为-5%和5%,判断分位点分别选取已有样本分数的5%分位点和拒绝群体分位数的95%分位点,而好坏比差异具体指DELTA = (LogOdds(kn) – LogOdds(asg))/ LogOdds(kn)。
如果好坏样本的最终分配结果满足以上要求,则推测过程完成,否则,将要对已有样本模型或者分配过程中的KN_SCORE与好坏比率之间的关系进行调整,并重新进行以上步骤进行测试。
6、评分校准
评分校准是通过线下转换,将最终模型评分与好/坏比(odds)建立一定对应关系的过程,在最终模型确定后进行,用于转化最终的模型分数。
以逻辑回归为例,申请评分卡模型评分校准需要三个必要参数:基准评分,基准odds和PDO(odds翻倍所需增加的分值)。
评分校准公式为:模型评分=基准评分+PDO*(ln(odds)-ln(基准odds))/ln(2)。
由于逻辑回归的输出概率和真实概率本身具有较好的一致性,上述的分数校准过程实际上更接近尺度变,在使用SVM、Boosted 相关算法等机器学习模型进行评分模型开发时,则需要使用Platt Scaling、Isotonic Regression等方法来进行分数校准,以保证预测概率和输出分布接近于真实情况。
此外,如果因为抽样或者数据可得性等原因导致建模样本的好坏比与实际生产不一致时,则需要通过建立建模样本正样本的概率与实际情况正样本概率的映射关系来对预测概率进行校准,来还原真实水平的违约概率。
7、验证模型
为保证申请评分模型的有效性,待模型开发完成之后,需要进行跨时间验证,以检验在当前数据环境下客群的稳定性、模型区分力、稳定性以及排序力的表现等。
申请评分模型验证中,K-S值统计差值的绝对值在4以内,GINI系数统计差值的绝对值在8以内,可以认为模型好坏区分能力是较为稳定,未发生较大变化。
在稳定性考察中,PSI指数的参考阈值为0.1,如果PSI大于0.1,则表明模型不够稳定,需要对模型进行调整。
在排序能力考察中,通过观察模型在跨时间验证数据上“好样本”/“坏样本”在不同分数段上分布的变化是否平滑,来检测申请评分卡在跨时间验证时点是否具有排序能力。
Related Articles
浅析信用卡业务A卡评分模型的构建(二):模型设计的技巧
作者:曾洪勇 职位:高级数据科学家替代数据和高级分析法:未来金融机构的选择
作者:高级产品经理 Rahmi Pramesti (拉米帕·梅斯蒂)、数据分析师 Andre Dana(安德烈·达纳)

