
中

作者:ZHOU YINAN 职位:Research Scientist
在如今的e-KYC服务中,已有多种人工智能技术正在得以广泛应用。比如,读取、审核银行账单时,常运用光学识别技术(OCR),假证检测技术(ID Forgery);人证比对审核时,常运用人脸识别技术(Face Recognition),基于RGB图像的活体技术(Face Anti-spoofing)等等。
在这其中,有些人工智能技术,比如光学识别,仍处于算法研究阶段,但人脸识别技术,假证检测技术的研究则早已从算法研究进入了数据驱动研究阶段,即进一步关注如何利用更多数据,提高模型准确率,在更多应用场景中,实现更高鲁棒性。
数据,是人工智能发展的源泉,标注数据,是驱动人工智能技术实现更广泛应用的主要动力。然而,在当今技术发展进程中,虽然我们已能捕获海量数据,但如何高效获取标注数据,却一直面临诸多挑战——目前,数据标注主要采取人工标注方式,标注数据的质量与效率容易受到数据标注团队人员能力、时间等客观因素影响。那么,在未来技术发展中,对于数据的处理与应用,到底有哪些可探索的途径呢? 本文将重点介绍在实践中广泛应用的半监督学习方法。
一、 什么是半监督学习?
半监督学习(Semi-supervised Learning)是无监督学习与监督学习相结合的一种学习方法。半监督学习在训练过程中,使用大量未标注数据,并将它们与少量标注数据结合使用,此举可以显着提高学习准确度。
半监督学习与主动学习的差别,则在于主动学习训练中,全部使用标注数据,但是在半监督学习中,标注数据与大量未标注数据同时存在。
半监督学习数据处理方法常应用于场景复杂度不高的算法中,比如人脸识别、活体检测,这两类都是简单的多分类问题或者二分类问题。
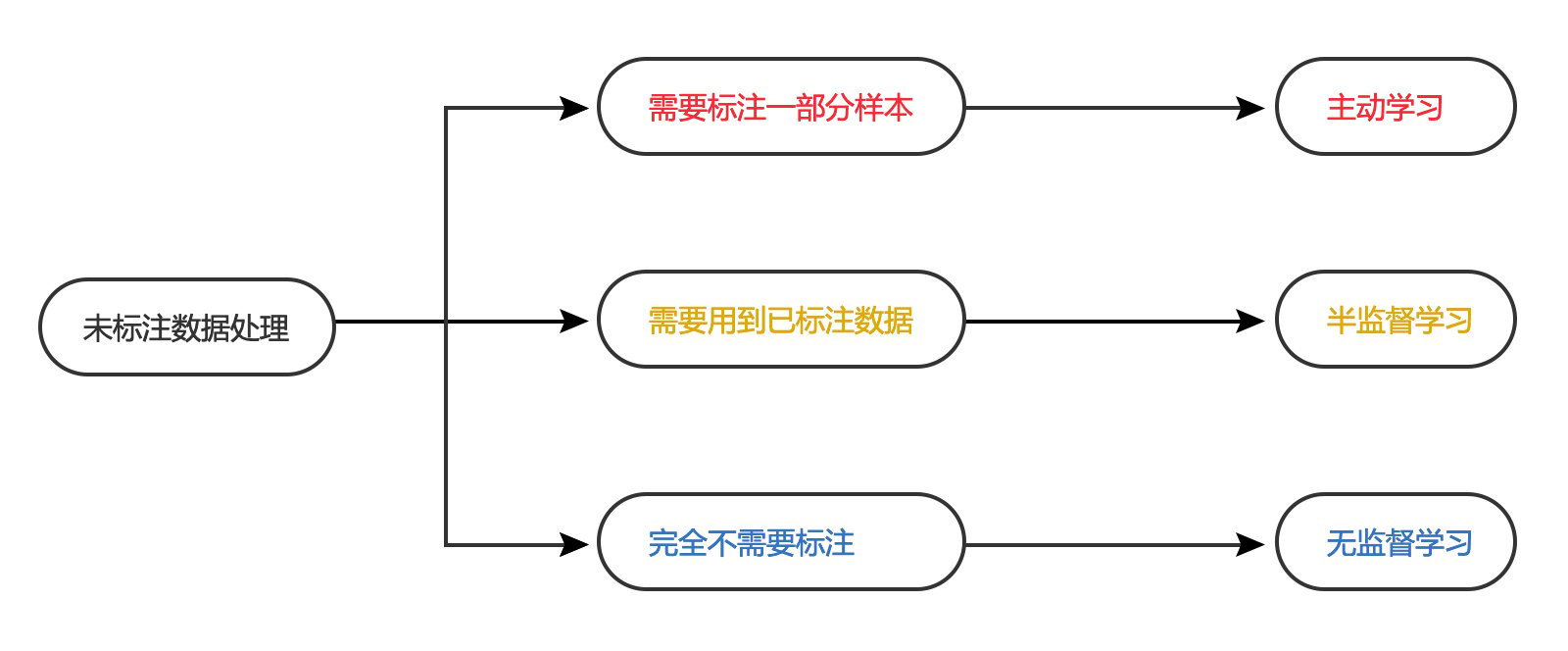 图1:常用数据处理方法与需求数据类型一览
图1:常用数据处理方法与需求数据类型一览
二、 半监督学习常见算法
由于半监督学习中存在大量未标注数据,因此,其相关算法需要具备强大的先验条件,才可更好应用此类非标注数据。根据不同的先验条件,半监督学习可以分为以下这些算法:
1. 分布先验(Minimize Entropy)
分布先验的先验条件为:如果一个模型具有很强的泛化能力,那么模型一定会将一个未标注的样本分好类,即这个样本的entropy loss会很低,用数学方法来表示,则为:
对于一个多分类问题,已标注样本集合用X表示,label用L表示,未标注样本集合用U表示,对于一个好的模型M,我们希望M能将X分对类,同时对U具有最小的entropy,假设这个模型在U上的预测label为L,则Loss可以表示为:
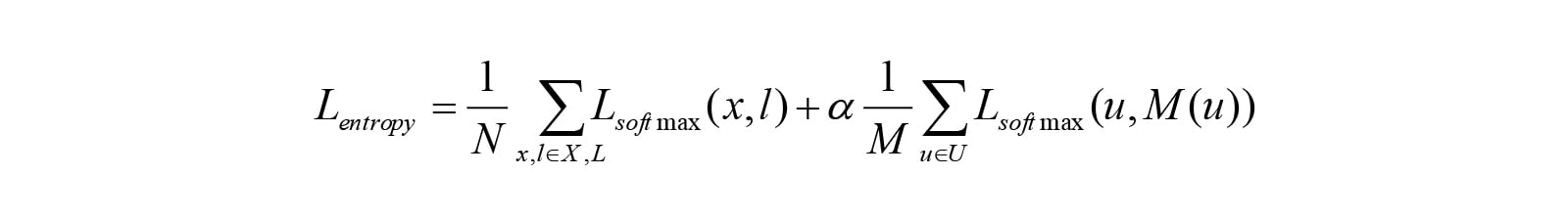
2. 数据增强先验(Consistency Regularization)
数据增强先验条件为:一个好的模型对于一个样本及其数据增强之后的图片预测的结果很相近,用数学方法来表示,则为:
用Aug(U)表示对U进行数据增强之后得到的数据集,则Loss可以表示为:
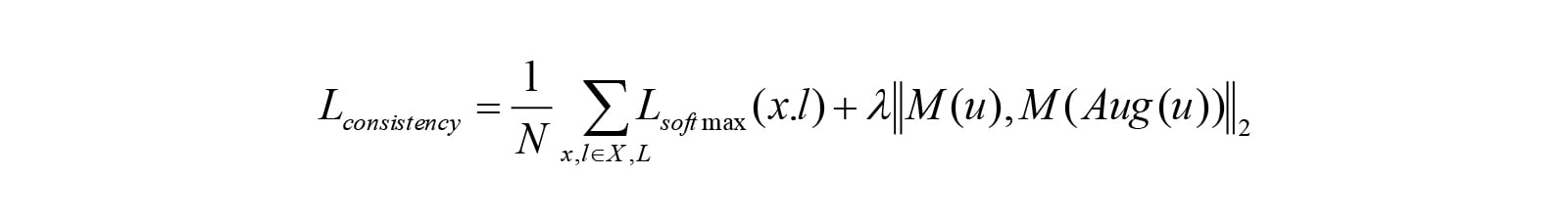
3. 标注样本先验
标注样本先验条件为:假设已标注的样本训练出来的模型足够出色,能够将U大部分都预测准确,此时我们可以让模型给为标注数据U打上伪标签(pseudo label),通过某种自动选取方法进行迭代训练,最终得到模型,单次迭代Loss可表示为:
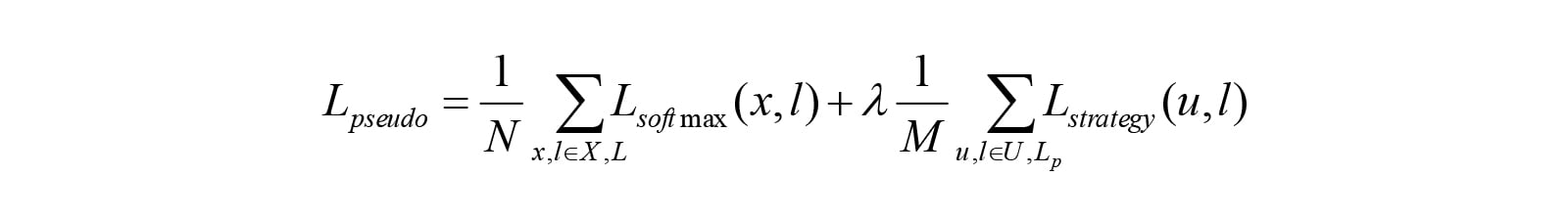
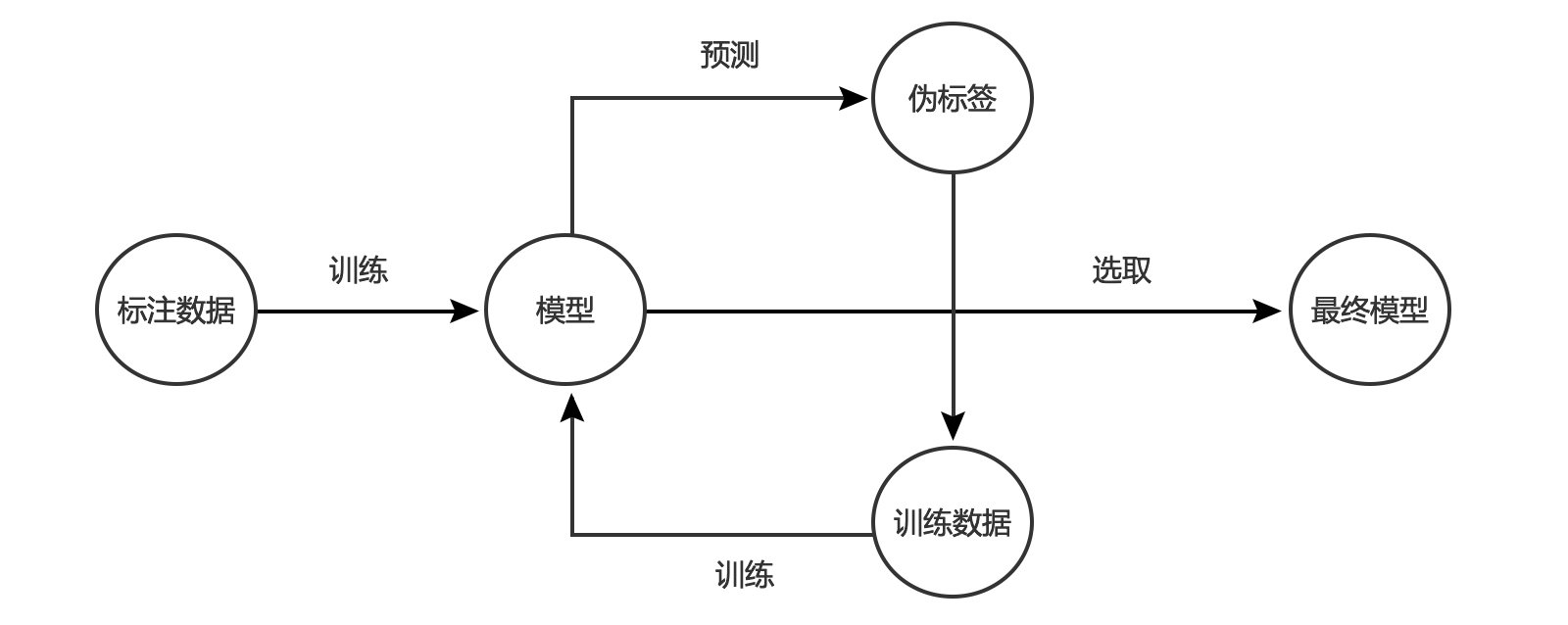 图2:标注样本先验算法流程示例
图2:标注样本先验算法流程示例
三、 半监督学习的应用实践:假证检测
1. 场景描述:
用户上传一张拍摄的证件,模型需要判断这张照片是真实拍摄的(valid)还是伪造的(fake),伪造的种类包括:翻拍,照片替换,文字修改等。
2. 数据集:
 3. 选取策略:
3. 选取策略:
如下图所示,中间的0.5代表分界面,小于0.5的表示fake samples,大于0.5的则是valid samples;分别选取两端中间(橙色部分)的样本加上伪标签和已标注样本一起进行训练。
如果样本过于靠近分界线,则说明模型无法准确判断这个样本的类别,此时伪标签没有意义;而如果样本过于远离分界线,加上伪标签也不会产生很大的loss。
 图3:假证检测场景半监督学习应用的选取策略
图3:假证检测场景半监督学习应用的选取策略
4. 结论:

经过半监督学习,相对于监督学习,假证检测模型的准确率在各个指标上都有了提升,对于corner case(passrate=0.99)的情况尤其明显。
Related Articles


