
中

作者:刘振 职位:Java工程师
一、背景
最近系统出现了一次因为错误使用线程池而出现了内存溢出问题,遂打算写一篇线程池深入原理与实践,避免大家后面继续踩坑,更优雅的使用线程池。那么什么场景下该使用线程池、怎样设置核心参数、线程池是怎么运行调度的、实践参数应用设计等等,下面让我们带着这些问题来一探究竟。
二、什么场景下该使用线程池?
1.CPU密集型任务(任务数量较多但任务执行时间较短,占用资源较少)
例如OpenApi服务计费消息消费或者客户余额调用推送等消息类业务,这类业务往往处理较快,消息内容简单,但在高并发下,会瞬间产生大量任务数,造成瞬时大量线程开销,增加CPU压力,为了避免这种问题我们可以使用线程池进行线程数控制,达到控制并发的要求;
2.IO密集型任务 (任务数量较少但任务执行时间较长,占用资源较多)
常见于IO频繁的任务,例如客户账单的生成或者常见的日志收集场景,我们出现问题的业务场景就是这里。这类任务数量一般不会太多但是常常会消耗系统内存占用大量资源,为了避免这种问题我们可以使用线程池进行线程数量扩展,让系统处理IO的时候可以有空闲线程去处理别的任务,合理复线程。
3.IO&CPU密集型任务(任务数量多且占用资源多)
在这种特殊场景下,已经不是完全靠线程池就能保障系统的稳定性了的,需要多处业务共同发挥作用,例如:当任务瞬时数量特别多且时间效率低,占用资源多,那么这个时候就要考虑在业务产生方(流量入口)做业务限流处理,同时线程池尽可能设置更多的线程去处理任务,充分利用系统资源。
三、怎样设置核⼼参数?
首先聊这个话题之前我们要先简单了解一下为什么不推荐使用Executors提供的线程池进行线程池业务处理,主要原因有二:
其一,Executors封装好的线程池大多采用无界队列,很容易造成内存溢出,极不安全;
其二,为核心参数不可根据实际业务横向扩展,不够灵活,不适用于业务场景多变的情况。
书归正文,下面来说一下自定义线程池的方式及核心参数如何设置,自定义线程池一般采用ThreadPoolExecutor的方式进行线程池创建

主要参数的意义及运行逻辑:
corePoolSize(核心线程数)
当有任务需要执行时会先创建小于corePoolSize的线程去执行任务,并且线程池会保持核心线程数在池中,即使它是空闲的,除非设置了allowCoreThreadTimeOut为true,那么在keepAliveTime时间内便会被回收;
maximumPoolSize (最大线程数)
当workQueue满了之后会创建小于maximumPoolSize线程数执行任务,注意这里线程池可以创建线程的最大值不是corePoolSize+maximumPoolSize,而是maximumPoolSize。
keepAliveTime (线程最大存活时间)
核心线程数并不是执行完任务就被销毁掉,在有新任务到来且当前任务数大于核心线程数时,这时候这个参数就有了意义,它意味着新来的任务是否可以在keepAliveTime内复用已经任务执行结束了的线程,也就是空闲线程的存活时间;
workQueue(任务阻塞队列)
当创建线程数大于corePoolSize时就会把任务丢进workQueue进行排队,等待被take;
threadFactory(线程工厂)
自定义这个的好处是方便我们标记不同线程池的线程逻辑,更方便我们日常通过此排查问题;
RejectedExecutionHandler(拒绝策略)
当任务执行创建的线程数大于maximumPoolSize时就会触发定义好的拒绝策略(默认为直接抛弃任务),也可以继承这个类来实现自定义策略持久化存储不能处理的任务;
四、线程池怎么运行调度的?
首先我们来先了解下线程池的状态:
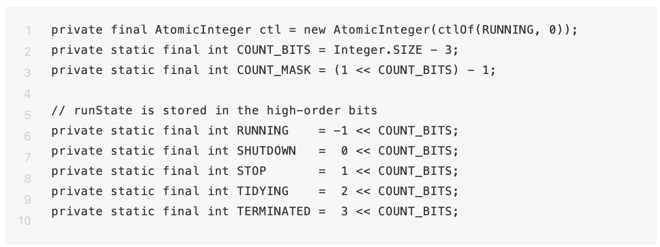
RUNNING:线程池处于这个状态下可以接受新的任务以及处理队列中的任务;
SHUTDOWN:不再接受新的任务,但是可以处理队列中的任务;
STOP:不再接受新的任务,不会处理队列中的任务,并且会中断处理中的任务;
TIDYING:所有任务都被终止,工作线程数量为0,此时线程的事务状态为TIDYING并且会运行钩子函数terminated(),进而线程池状态变为TERMINATED;
TERMINATED:线程池中一个重要的角色:Woker,它围绕着整个线程池的生命周期进行任务提交、任务运行,也就说它是作为线程池的工作线程进行运转的。

通过源码我们可以看到,Worker作为一个Runnable聪明的继承了AQS,这使得其天然具有AQS的优秀设计特性,其中不乏包括任务的排队唤醒、自旋加锁等等。
任务提交:
线程池的任务提交可分为两种:
带返回值

无返回值

大多数场景我们都是用submit的比较多,所以接下来的基于源码的运行原理探索也主要围绕着submit场景下来说,首先我们创建好一个线程池后,进行任务提交,那么依照源码我们来看底层的运行逻辑;

这里我们调用ExecutorService的submit方法后首先会将任务(Callable)封装成一个FutureTask丢给Executor的execute方法实现者(ThreadPoolExecutor)去执行

当线程池执行exceute时,首先会判断传入的task(RunnableFuture)是否为空,为空则抛出异常,否则直接进行主逻辑进行运行,如果当前工作线程数workerCountOf(c)小于调用addWorker方法创建任务工作线程Woker,如果创建失败则尝试入队,如果失败再addWorker尝试创建新的工作线程,如果失败则执行reject,进而触发拒绝策略;

在创建工作线程时,addWorker方法首先会检查线程池的运行状态、队列的空与否、是否已达到创建线程数峰值来决定是否要开启一个线程添加到
workers(HashSet,这也是为什么这里要添加可重入锁的一个原因,至于为什么这里没有用线程安全的集合例如:
ConcurrentHashMap
CopyOnWriteArrayList
CopyOnWriteArraySet等等。
个人觉得原因主要有两个:
其一,HashSet天然去重,再者HashSet本质上是具有HashMap的高效特性即效率更高;
其二,使用其他的集合容器,维护成本变高且不太符合)
中执行任务,如果满足条件则会通过Worker的构造方法创建工作线程并设置Worker状态(AQS中的State标识)为允许中断,然后调用worker的run方法执行任务;

我们可以看到在创建Worker时,添加了ReentrantLock可重入锁,并且进行了double check保证了程序运行的原子性,并且我们可以看到worker的run方法本质上是调用了runWorker方法,这也是线程池的核心设计runWorker;

关于runWorker的实现可以总结为如果传入的task(线程)为空则尝试不停从队列获取任务即getTask,不为空则直接执行任务,在之前任务之前会调用AQS的lock方法进行上锁,保证原子性。此外,线程池也在任务执行的前后为我们提供了扩展的方法beforeExecute(wt, task),afterExecute(task, thrown)。

看到这里我想我们应该知道线程池之所以可以不断执行client提交的任务,主要依赖于getTask这个方法的实现,其会一直尝试从队列获取任务,如果获取不到线程会被阻塞并被挂起(BlockQueue核心概念)并不会占用CPU资源,直到被唤醒。getTask直到线程池生命周期结束(包括正常和异常),下面是对应的主要逻辑;

综上便是线程池最主要的运行原理,接下来我们开始这次的硬菜:实践参数应用设计。
五、实践参数如何设计
其实关于这点我们上述主题已经介绍过一些了,下面会对其进行分析阐述,正常情况下我们设计线程池参数时首先要考虑的就是任务类型,不同的任务类型决定了我们给出的参数设置
目前看到最多的答案都是CPU任务类型采用n + 1,n*2,n为当前系统CPU核数。但是在我们复杂多变的系统中,这种设置往往站不住脚,经常会设置一遍后不断根据线上业务场景不断调试,但是我们要知道的是,一个系统设计好之后,轻易的修改,重启往往会带来一些麻烦或者故障。
书归正传,那么该如何设置线程池线程数以及队列长度呢?
我想最优解的答案应该是线程池动态化,那么具体该如何实现呢,其实juc已经为我们指明了方向,我们来翻看一下源码会发现:

这两个设置核心线程数的方法可以在运行时Runtime进行修改动态修改线程数,有了这一点我们完全可以将线程池参数配置在分布式配置中心中例如 Apollo、Nacos诸如此类可以动态修改配置的配置中心,这样一来我们的服务无需重启即可根据业务场景灵活调整线程池参数。
其实还有一个比较重要的参数,没错,阻塞队列,juc也没有为我们提供动态修改的方法,但是山重水复疑无路,柳暗花明又一村。没有的话我们可以造一个嘛,其实很简单,我们想一下,为什么juc不给我们提供这样一个方法呢,我们翻看LinkedBlockingDeque源码后就不难发现原因就在于阻塞队列的capacity被定义为final。
-
/** Maximum number of items in the deque */ -
private final int capacity; -
那么我们完全可以自定义一个CustomBlockingDeque,而后我们把capacity定义为可修改不就可以了。下面是实践的截图,供大家参考。 -
public static ThreadPoolExecutor getThreadPoolInstance(){ -
return new ThreadPoolExecutor(10,15,60, TimeUnit.SECONDS, -
new CustomBlockingQueue<>(20), customThreadFactory, new ThreadPoolExecutor.AbortPolicy()); -
} -
static ThreadPoolExecutor executor = getThreadPoolInstance(); -
static public void submitTask(String name){ -
for (int i = 0; i < 30; i++){ -
Callable<String> task = () -> { -
System.out.println(LocalDateTime.now()+"-" +Thread.currentThread().getName()+name+"核心线程数:" -
+executor.getCorePoolSize()+",最大线程数:" -
+executor.getMaximumPoolSize()+",当前排队数:" -
+executor.getQueue().size()+",任务完成数:" -
+executor.getCompletedTaskCount()+",队列大小" -
+(executor.getQueue().size()+executor.getQueue().remainingCapacity()) -
);
-
TimeUnit.SECONDS.sleep(10);
-
return null;
-
};
-
executor.submit(task);
-
}
-
}
-
-
public static void main(String[] args) throws InterruptedException { -
submitTask("参数改变前-"); -
TimeUnit.SECONDS.sleep(1); -
executor.setCorePoolSize(20); -
executor.setMaximumPoolSize(20); -
CustomBlockingQueue queue = (CustomBlockingQueue) executor.getQueue(); -
queue.setCapacity(100); -
submitTask("参数改变后-"); -
}


Related Articles
互金模型分类性能提升的诀窍——埋点数据特征提取深度学习与机器学习方法的比对实验记录
深度学习给人工智能诸多领域,比如计算机视觉(CV)、自然语言处理(NLP)等技术方向带来了巨大的突破和创新,大幅提升了相关模型的预测...什么是时序数据库?
作者:张斌 职位:后端工程师

