
中

作者:张斌 职位:后端工程师
一、时序数据的基本概念
在了解时序数据库之前首先要了解什么是时序数据,Time Series Data是指按照时间顺序记录系统、设备状态变化的数据,时序数据有如下几个维度:
-
Measurement:度量,相当于关系型数据库中的 table
-
Data point:数据点,相当于关系型数据库中的 row。
-
Time:时间戳,代表数据点产生的时间。
-
Field:度量下的不同字段。比如位置这个度量具有经度和纬度两个 field。一般情况下存放的是随时间戳而变化的数据。
-
Tag:标签。一般存放的是不随时间戳变化的信息。timestamp 加上所有的 tags 可以视为 table 的 primary key。
二、时序数据库与其他数据存储的对比
-
关系型数据库:尽管时序数据库中的Measurement,Data Point,Filed,Tag都似乎能在关系型数据库中找到对应,而且时序数据库还有类SQL的交互方式,但是对于关系型数据库中的CRUD,时序数据库更侧重其中的C和R的高效,在海量数据聚合分析更强。
-
Elasticseach:Elasticseach虽然主打大数据量的搜索,但是高效的处理大量数据读写操作也可以起到时序数据库的作用。
三、使用场景
时序数据看起来就是一个时间轴,表明了一些数据维度随着时间的变化,通常这些数据以插入为主,没有什么更新操作。由于这些特点,时序数据库诞生了。时序数据库目标实现高性能的读写,实时分析。被广泛应用在物联网设备信息采集,金融数据分析及可视化等众多场景当中。其中,InfluxDB是一个开源时序数据库诞生于2013年,起初设想应用于高性能的监控和告警,下面将以InfluxDB为例带大家体验时序数据库。
四、体验InfluxDB
InfluxDB是一个开源的时序数据库,而且1.0使用类SQL的语句查询,借用InfluxDB带大家体验一下时序数据库。
五、安装与启动
以MacOS为例下载地址:https://dl.influxdata.com/influxdb/releases/influxdb-1.8.10_darwin_amd64.tar.gz
解压后到/influxdb-1.8.10-1/usr/bin目录下,执行可启动sudo ./influxd -config ../../etc/influxdb/influxdb.conf
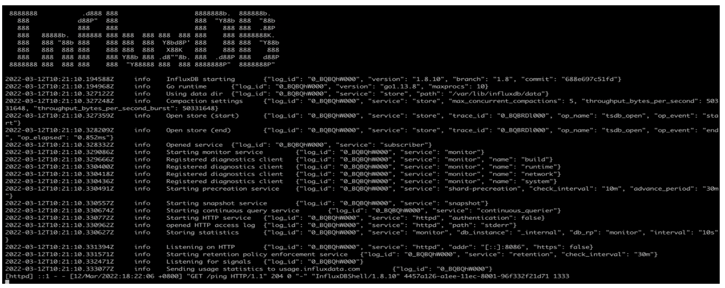
继续在bin目录下执行./influx就可以进入InfluxDB shell直接食用类sql的语句进行操作。
六、数据库写入
创建数据库CREATE DATABASE test
列出所有数据库SHOW DATABASE test
使用数据库USE test
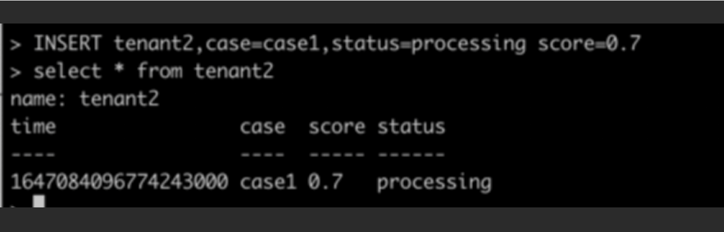
插入数据使用insert,后面解释具体的格式,这里我们做一条插入,使用select进行查询:
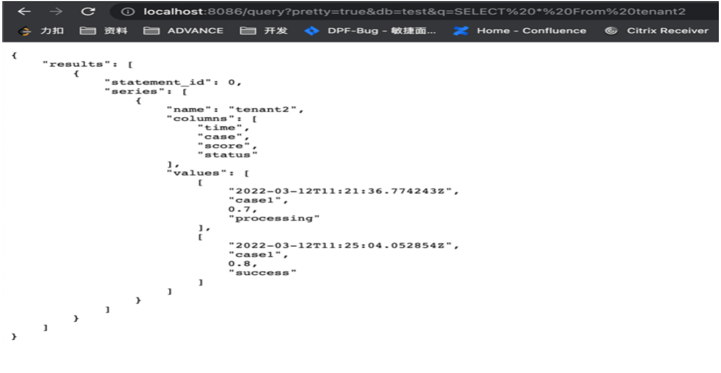
七、http方式操作
InfluxDB使用HTTP作为方便和广泛支持的数据传输协议,例如GET /query
InfluxDB插入数据格式
将数据写入InfluxDB需要按照一定的文本格式:

-
Measurement:就是类似于结构数据的表明,在插入时是必须的。
-
Tag set:数据的标签,有点类似于主键,可以没有或者多个,多组Tag之间写法上使用不带空格的逗号分开,写法为Measurement ,<tag_key>=<tag_value>,<tag_key>=<tag_value>。注意:tag是会加索引的。
-
Field set:每行数据至少有一个Field set多组使用使用不带空格的分隔,格式为<field_key>=<field_value>。
-
Timestamp是可选字段,必须使用空格分开。Timestamp时间戳虽然可选,但是不写将使用服务器时间进行填充。
-
其中Measurement与Tag set使用逗号分隔,Measurement或者Tag set与Field Set使用空格分隔,field set与Timestamp使用空格分隔。
不同组件的数据格式
-
Measurement,Tag keys,Tag values,Field keys必须为String类型。
Field value可以是整数、浮点数、字符串和布尔值。其中字符串使用双引号表示,布尔值使用t,T,true,True,TRUE表示TRUE,f,F,false,False,FALSE表示FALSE。
-
Timestamp时间戳
数据主键
对于InfluxDB,同一个Measurement下,Timestamp加Tags作为唯一标识,相同的标识插入但是FieldSet不同会做合并,冲突部分以新的Field为准。
数据查询
查询语句类似sql查询方式

复杂操作
另外InfluxDB支持类如group by,count等等聚合以及limit,offset的分页操作。
八、使用InfluxDB需要注意的几个方面
1. 在InfluxDB中可以指定retentionPolicy,不指定也会有默认的策略,特别注意如果中期调整策略,过期的数据会被立刻清除。
2. Tag不是必须的,但是如果在查询中经常使用到或者使用到了GroupBy或者InfluxQL函数推荐使用Tag,尤其注意Tag Value只能是字符串,如果字段value是数字类型则无法使用Tag存放。
3. InfluxDB的数据存放在shard中,以tsm的文件形式存放在磁盘上,shard group受retentionPolicy管理。
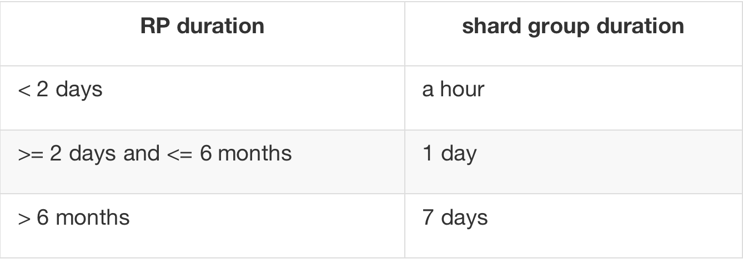
在retentionPolicy触发时会对应删除相应shard,提高shard group的持续时间可以改善压缩,提高写入的速度。
九、总结
对于时序数据库,本文针对其特点和InfluxDB1.0做了简单的介绍,在2.0中influxDB又做了极大的改动,本文只是抛砖引玉,祝大家在数据存储上都能找到合适的工具,数据库永远稳定高效。
Related Articles


